
Research Overview
On this page...
On this page I describe my main research interests of computational complexity theory. The description is mostly meant as a background for those not familiar with computational complexity, or even those not familiar with computer science at all. For those familiar with computational complexity who want to learn more about my research, please see my publications.
I continue to research within computational complexity theory and theoretical computer science. I also collaborate on other projects at times; see my publications for some examples. This page may be updated at some point to provide some background particular to projects outside of computational complexity... See also current and upcoming projects.
The rest of this page:
Solving Computational Problems,
Computational Intractability,
Randomized Algorithms,
My Research,
Learn More.
My research in computational complexity theory focuses on which
problems can be solved efficiently by computer programs and which cannot.
To get a feeling for what this means, first consider some examples of
computational problems.
Multiplication Given two (potentially very large) numbers,
multiply them. A small example would be to multiply
23 and 11. It is easy to verify that their product is 253. A larger
example would be to multiply 234578358 and 89485651. Doing this calculation
on paper would be tedious, but following the method of multiplication
taught in elementary school, one could compute the product within a few
minutes. The correct answer is 20991397076141058.
A computer performs calculations much much faster than we can on
paper, and can compute the product of numbers with even millions of
digits in fractions of a second. Factoring Given a (potentially very large) number, determine
the prime factorization of the number. A small example would be to
factor 28. It is easy to verify the factorization of 28 is 2*2*7.
Another small example is to factor 13. 13 itself is prime, so its
factorization is simply 13. A larger example is the number 2353997. How would one find the prime
factors? One method is simply trial and error. Attempt to divide
2353997 by 2; if there is a remainder of 0, then 2 is a factor. Next
attempt to divide 2353997 by 3; if there is a remainder of 0, then 3
is a factor. Continue doing this all the way up to 2353997 (actually,
going up to $\sqrt{2353997}$ is good enough). By trying all of the possibilities, we discover all of the
factors of 2353997, but how long does the process take? We
perform 2353997 different division problems to finish trying all
possibilities. For a computer, performing this many divisions does
not take too long, but as numbers get even larger the factoring
problem becomes too difficult even for computers to perform. For a
number that has a few thousand digits, it would take even the fastest
supercomputers billions of years to finish all the computations needed. We see a great difference between the multiplication and factoring
problems. Whereas multiplication can be achieved very efficiently on
computers, the process we outlined for factoring is very slow. Graph Connectivity A graph is a picture that has
vertices and edges. The vertices can be thought of as
cities, and the edges as roads between the cities. Or, the vertices
can be thought of as people, and the edges as connections between them
(e.g., two people are connected by an edge if they are friends on
Facebook). Graphs have many different applications; one example is
when a website such as google.com or mapquest.com gives directions
from one location to another.
The graph connectivity question asks whether a graph is connected.
For each pair of cities, can you get from one to the other?
Consider the graph on the left. At first glance, it is not obvious
whether the graph is connected or not. But a relatively
Applying this gives the sequence of graphs below. After the third step
there are no new cities connected to the blue vertices that have not
yet visited, yet we have not reached all vertices - thus the graph is
not connected.
As with multiplication,
computers can automate this process to determine connectivity on
graphs with millions of cities in just fractions of a second.
Somewhat
similar procedures can be used to find the "best/shortest"
directions between locations on a map.
Graph Clique For the graph clique problem, we think of
the graph as indicating which people are friends with each other on Facebook.
The question is -- what is the largest group of people that are all
friends with each other? Such a group of people is called a
clique.
Thus the clique problem, like the factoring problem, is one that can be
very time-consuming to solve, even on a computer.Solving Computational Problems
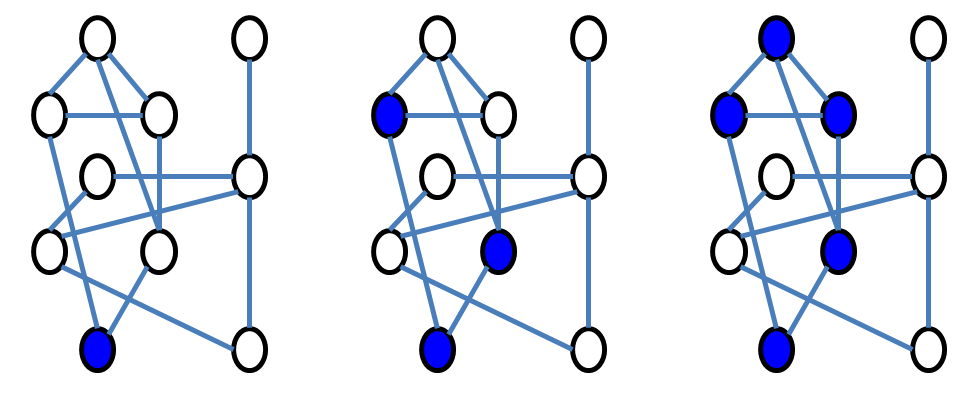
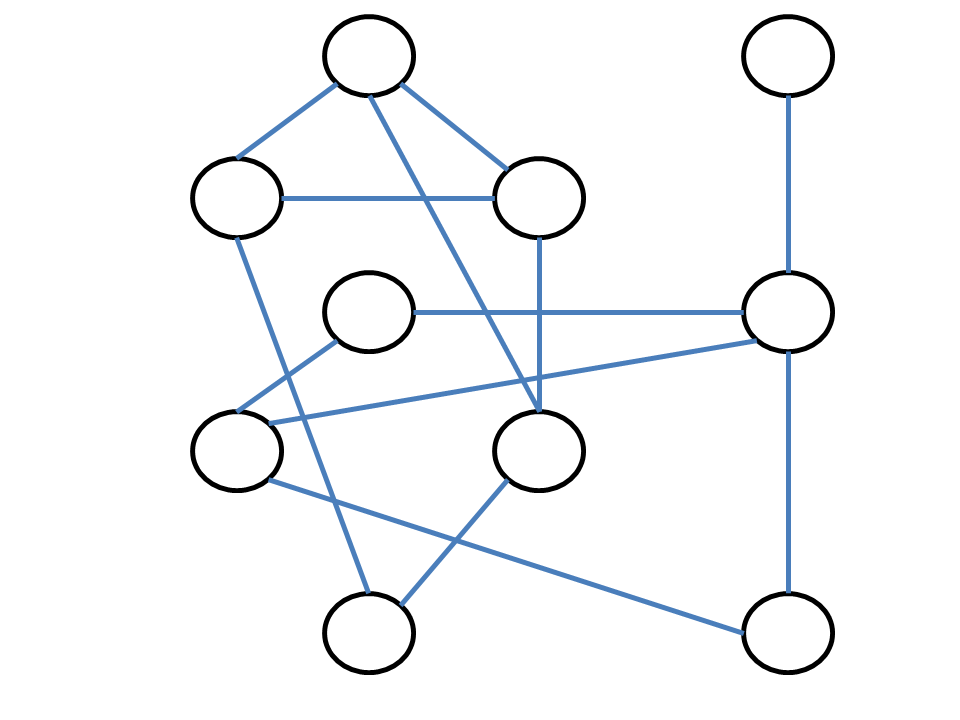 simple
procedure
lets us find the answer. Pick a city on the left and color
it blue; then color all cities that are connected to that city blue;
then color all cities connected to those cities blue. We keep doing
this until there are no more cities we can get to by taking an edge
from one of the blue cities.
simple
procedure
lets us find the answer. Pick a city on the left and color
it blue; then color all cities that are connected to that city blue;
then color all cities connected to those cities blue. We keep doing
this until there are no more cities we can get to by taking an edge
from one of the blue cities.
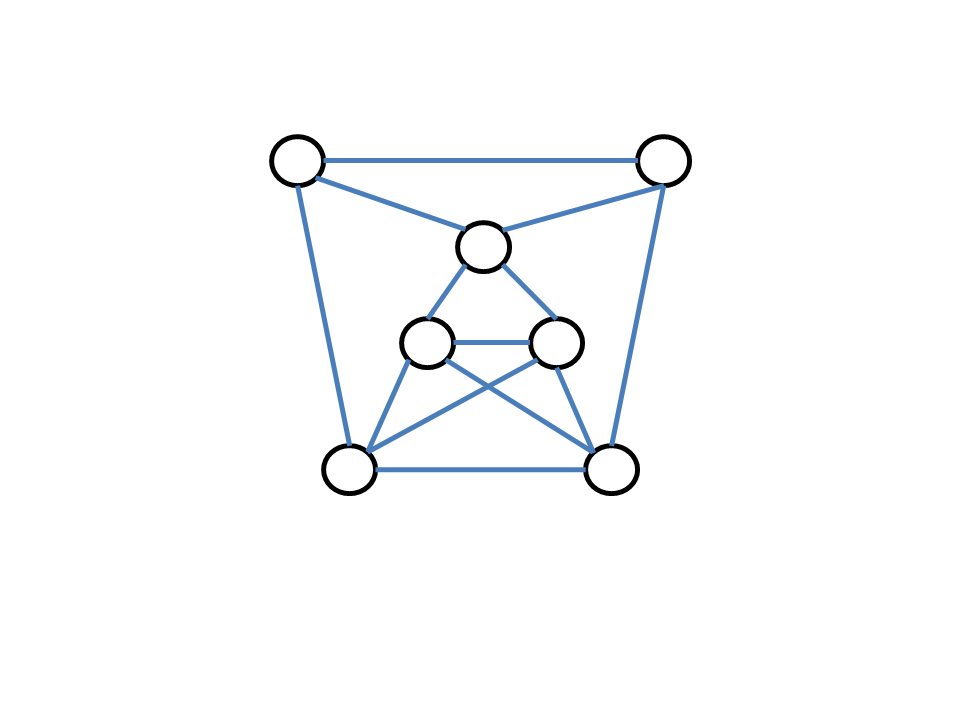 In the graph on the left, the top three vertices ("people")
form a clique of size three (of three people). But we ask, what is
the largest clique in the graph, is there one larger than three? One
way to find out is to try all possible groups of four people. This is
pictured below. Only the bottom-right group of four vertices
checks out as being a clique. On this small graph, this can be done by
hand. For larger graphs (for example, the Facebook graph would have
hundreds of millions of vertices), there are just too many
possibilities to consider.
In the graph on the left, the top three vertices ("people")
form a clique of size three (of three people). But we ask, what is
the largest clique in the graph, is there one larger than three? One
way to find out is to try all possible groups of four people. This is
pictured below. Only the bottom-right group of four vertices
checks out as being a clique. On this small graph, this can be done by
hand. For larger graphs (for example, the Facebook graph would have
hundreds of millions of vertices), there are just too many
possibilities to consider.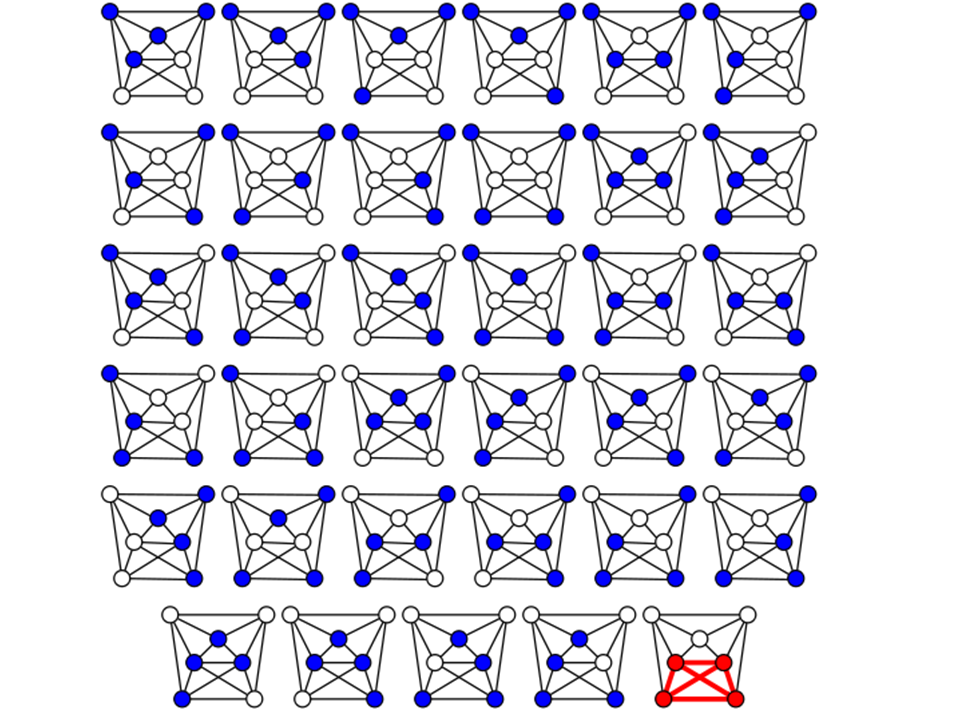
Computational Intractability
Mathematicians and computer scientists have been searching for the most efficient ways to solve computational problems like those described above for hundreds of years. Many problems, such as multiplication and graph connectivity, can be solved efficiently. For other problems, such as factoring and graph clique, we still do not know of any way to solve the problems that is significantly better than the "brute force" approaches described above. The question is whether these problems truly are computationally intractable and cannot be solved efficiently by any algorithm, or perhaps we just have not been clever enough to discover the best ways to solve the problems. One of the main aims of my research area, computational complexity, is to prove that problems like factoring and graph clique are indeed intractable -- that there is no possible way to program a computer to solve these problems efficiently.
P versus NP problem Some progress has been made, but the task has been exceedingly difficult. A final solution to whether these problems is intractable or not is called the "P versus NP" problem. P is shorthand for the class of problems that can be solved efficiently on computers; NP is a class of problems, including problems like factoring and graph clique, for which correct solutions can be easily checked even if they are difficult to find. The P versus NP problem asks if the NP problems can be solved efficiently and is included in the list of seven problems that the Clay Mathematics Institute chose in 2000 as the most important open problems to solve in this century; a solution to any of the seven "Millennium Prize" problems comes with a one million dollar reward (and fame, glory, and likely a distinguished professor appointment anywhere in the world). Theory of computing researchers are regularly polled as to when they expect the "P versus NP" problem to be solved; the estimates normally range from 20-200 years, or never.
Randomized Algorithms and The Bright Side of Hardness
The final solution to the P versus NP problem may be still far off, but the theory of computing community has made great progress on other problems. A very important discovery in the 1970's and 1980's is that computational intractability can actually be useful. Modern cryptosystems such as those used for security on the Internet rely on the conjecture that problems such as factoring cannot be solved efficiently.
Randomized Algorithms Another potential application of computational hard problems is in the area of randomized algorithms -- which are ways of solving problems on a computer that take advantage of randomness. Many are familiar with random sampling due to polling results that are reported by news outlets. Just as being able to sample at random is very valuable in election polling, being able to choose at random is also very useful in solving problems on computers. One example is that of estimating the area or volume of an object with a very complicated shape. An algorithm that performs reasonably well is to think of "throwing darts" at random towards the object.

The fraction of darts that "hit" the object can give an estimate for the total area of the object. If we throw enough darts at random, then with very high probability this gives a pretty close estimate of the true area or volume of the object.
Derandomization My research focuses on derandomization -- taking procedures that use random choices and trying to convert the procedures into ones that do not need random choices. Making truly random choices is often difficult or expensive; we would like to have the benefits of randomized algorithms without the costs. A very significant line of research since the 1990's has shown that we can indeed "remove randomness" from many randomized procedures -- by using computationally intractable problems.
Imagine a procedure that needs access to random choices. We imagine the random choices as inputs to the procedure. For area or volume estimation, the inputs are coordinates of points, and the procedure itself simply calculates the percentage of the points that lie within the region being considered. Imagine replacing the random numbers with numbers that result from some very complicated process. For example, start with the current number of seconds on your clock as your first number, say 31. Then square that number and look at the last two digits to obtain the second number; 31*31 = 961, the last two digits are 61, so the second random-looking number is 61. The next random-looking number would be 21 (the last two digits of 61*61=3721). The process could be repeated until we have as many random-looking numbers as needed.
The process seems random-looking to the human observer, but how can we know for sure there is not a simple pattern lurking in the supposedly random-looking numbers? Computational complexity has shown that if we use a computationally intractable problem as the basis of generating the random-looking numbers, then there can be no simple pattern (see this monograph for the details). The result is a pseudorandom sequence of numbers -- one that can be used in place of true random numbers when used for area estimation or any other randomized algorithm.
My Research
My research has focused in two main areas.
- Proving problems are computationally intractible, and studying relationships between different computational problems.
- Using conjectured intractable problems for derandomization, and studying other properties of randomized algorithms.
Learn More
Are you interested in learning more about computational complexity theory? I suggest you click some of the links above (most of which point to various wikipedia pages) and explore those articles. For a more in depth and thorough look at complexity, I suggest looking at a complexity theory textbook or taking a course in complexity theory. Of course, you probably want to have some background in mathematics and computer science to do that...